
本稿執筆の目的
- タイムリーなユーザーインサイトを誰もが簡単に収集可能にすること
- プログラミング言語の学習コスト削減
- Twitter運用をアウトソースするための準備
本稿を読むメリット
- Pythonの基礎知識がなくても、ツイートをスクレイピングできる
- 指定アカウントのツイート直近3,000件取得できる
- 指定キーワードを含むツイート直近3,000件取得できる
本稿の対象読者
- SNS上のユーザーインサイトを収集したいと考えている人
- Twitter Developperの登録が完了している人
※2点目のハードルがやや高いので後日記事化します。
実行環境
- Google Colaboratory(Visual Studio Code等でも可)
- Python 3.6.6
- mac Catalina
実行方法
step
1Google Colaboratoryにアクセス
Google Colaboratoryにアクセスします。
step
2ノートブックを新規作成
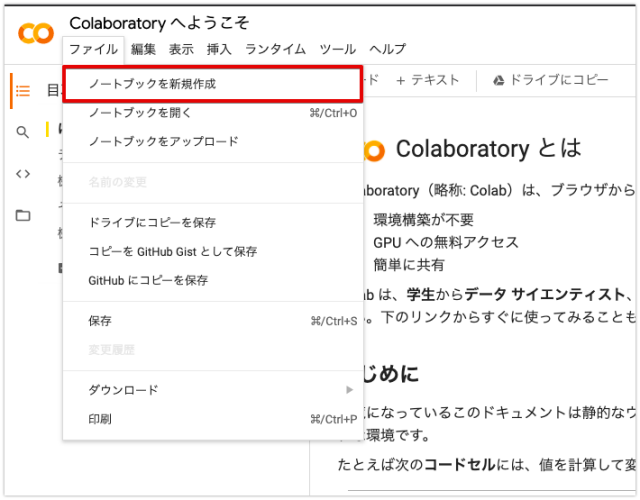
ログインを求められるので、Googleアカウントにログインします。
step
3本稿「実装コード_Python」を貼り付け
step
4Twitter Developperから取得したAPIキーを入力
コード内で空欄になっているCK、CS、AT、ASを埋めます。
※Twitter Developperへの登録が完了していない人は、登録申請が必要です。(別途、記事化します)
step
5取得条件「キーワード」または「アカウント名」を入力
# 検索条件を指定して取得 (screen_nameまたはキーワード)
targets = ['recruiter_take','Syukatsu_Muso']
上記のように、取得対象の「キーワード」または「アカウント名」を入力します。
注意ポイント
「キーワード」を指定する場合と「アカウント」を指定する場合で呼び出すメソッドが異なるため、以下のように必要に応じてコメントアウトが必要です。
キーワードを指定する場合
以下をコメントアウトします。
getter = TweetsGetter.byUser(target) #ユーザー名(screen_name)検索の場合はこっち
アカウントを指定する場合
以下をコメントアウトします。
getter = TweetsGetter.bySearch(target) #キーワード検索の場合はこっち
step
6プログラムを実行する
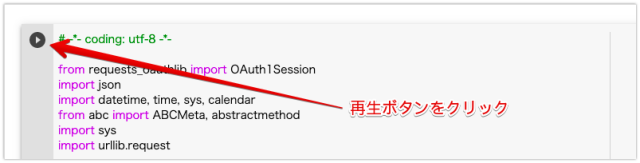
「再生ボタン」のようなアイコンをクリックすると、プログラムが実行されます。
プログラム実行後、スクレイピングしたツイートがログに出力されていきます。
step
7CSVをダウンロード
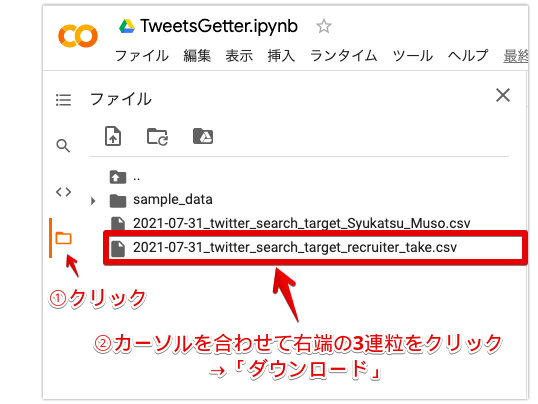
プログラムを実行すると、指定した「キーワード」または「アカウント」ごとにCSVが出力されます。
Google Colaboratoryの画面左端にあるサイドバーから「フォルダ」アイコンをクリックし、表示されたダウンロードしたいCSVファイルにマウスオーバーし、ファイル右側の3連粒をクリック。「ダウンロード」をクリックすると、自身のPC(ローカル)に対象ファイルが保存されます。
当該プログラムによるアウトプットサンプル

L列以降は私がスプレッドシート上で追加したものです。K列までが本稿で紹介しているプラグラムで出力されるデータです。
実装コード_Python
# -*- coding: utf-8 -*-
from requests_oauthlib import OAuth1Session
import json
import datetime, time, sys, calendar
from abc import ABCMeta, abstractmethod
import sys
import urllib.request
# TwitterAPIキー
CK = '' # Consumer Key(Twitter Developperで取得)
CS = '' # Consumer Secret(Twitter Developperで取得)
AT = '' # Access Token(Twitter Developperで取得)
AS = '' # Accesss Token Secert(Twitter Developperで取得)
# リダイレクトしないハンドラークラス
class NoRedirectHandler(urllib.request.HTTPRedirectHandler):
# HTTPRedirectHandler.redirect_request をオーバーライド
def redirect_request(self, req, fp, code, msg, hdrs, newurl):
self.newurl = newurl # リダイレクト先URLを保持
return None
# リダイレクト先 URL を取得する関数
def get_redirect_url(src_url):
# リダイレクトしないハンドラーをセット
no_redirect_handler = NoRedirectHandler()
opener = urllib.request.build_opener(no_redirect_handler)
try:
with opener.open(src_url) as res:
return None # リダイレクトしない URL だった
except urllib.error.HTTPError as e:
if hasattr(no_redirect_handler, "newurl"):
return no_redirect_handler.newurl # リダイレクト先 URL を返す
else:
raise e # リダイレクト以外で発生した例外なので投げ直す
def YmdHMS(created_at):
time_utc = time.strptime(created_at, '%a %b %d %H:%M:%S +0000 %Y')
unix_time = calendar.timegm(time_utc)
time_local = time.localtime(unix_time)
return time.strftime("%Y/%m/%d %H:%M:%S", time_local)
class TweetsGetter(object):
__metaclass__ = ABCMeta
def __init__(self):
self.session = OAuth1Session(CK, CS, AT, AS)
@abstractmethod
def specifyUrlAndParams(self, keyword):
'''
呼出し先 URL、パラメータを返す
'''
@abstractmethod
def pickupTweet(self, res_text, includeRetweet):
'''
res_text からツイートを取り出し、配列にセットして返却
'''
@abstractmethod
def getLimitContext(self, res_text):
'''
回数制限の情報を取得 (起動時)
'''
def collect(self, total = -1, onlyText = False, includeRetweet = False):
'''
ツイート取得を開始する
'''
#----------------
# 回数制限を確認
#----------------
self.checkLimit()
#----------------
# URL、パラメータ
#----------------
url, params = self.specifyUrlAndParams()
params['include_rts'] = str(includeRetweet).lower()
# include_rts は statuses/user_timeline のパラメータ。search/tweets には無効
#----------------
# ツイート取得
#----------------
cnt = 0
unavailableCnt = 0
while True:
res = self.session.get(url, params = params)
if res.status_code == 503:
# 503 : Service Unavailable
if unavailableCnt > 10:
raise Exception('Twitter API error %d' % res.status_code)
unavailableCnt += 1
print ('Service Unavailable 503')
self.waitUntilReset(time.mktime(datetime.datetime.now().timetuple()) + 30)
continue
unavailableCnt = 0
if res.status_code != 200:
raise Exception('Twitter API error %d' % res.status_code)
tweets = self.pickupTweet(json.loads(res.text))
if len(tweets) == 0:
# len(tweets) != params['count'] としたいが
# count は最大値らしいので判定に使えない。
# ⇒ "== 0" にする
# https://dev.twitter.com/discussions/7513
break
for tweet in tweets:
if (('retweeted_status' in tweet) and (includeRetweet is False)):
pass
else:
if onlyText is True:
yield tweet['text']
else:
yield tweet
cnt += 1
if cnt % 100 == 0:
print ('%d件 ' % cnt)
if total > 0 and cnt >= total:
return
params['max_id'] = tweet['id'] - 1
# ヘッダ確認 (回数制限)
# X-Rate-Limit-Remaining が入ってないことが稀にあるのでチェック
if ('X-Rate-Limit-Remaining' in res.headers and 'X-Rate-Limit-Reset' in res.headers):
if (int(res.headers['X-Rate-Limit-Remaining']) == 0):
self.waitUntilReset(int(res.headers['X-Rate-Limit-Reset']))
self.checkLimit()
else:
print ('not found - X-Rate-Limit-Remaining or X-Rate-Limit-Reset')
self.checkLimit()
def checkLimit(self):
'''
回数制限を問合せ、アクセス可能になるまで wait する
'''
unavailableCnt = 0
while True:
url = "https://api.twitter.com/1.1/application/rate_limit_status.json"
res = self.session.get(url)
if res.status_code == 503:
# 503 : Service Unavailable
if unavailableCnt > 10:
raise Exception('Twitter API error %d' % res.status_code)
unavailableCnt += 1
print ('Service Unavailable 503')
self.waitUntilReset(time.mktime(datetime.datetime.now().timetuple()) + 30)
continue
unavailableCnt = 0
if res.status_code != 200:
raise Exception('Twitter API error %d' % res.status_code)
remaining, reset = self.getLimitContext(json.loads(res.text))
if (remaining == 0):
self.waitUntilReset(reset)
else:
break
def waitUntilReset(self, reset):
'''
reset 時刻まで sleep
'''
seconds = reset - time.mktime(datetime.datetime.now().timetuple())
seconds = max(seconds, 0)
print ('\n =====================')
print (' == waiting %d sec ==' % seconds)
print (' =====================')
sys.stdout.flush()
time.sleep(seconds + 10) # 念のため + 10 秒
@staticmethod
def bySearch(keyword):
return TweetsGetterBySearch(keyword)
@staticmethod
def byUser(screen_name):
return TweetsGetterByUser(screen_name)
class TweetsGetterBySearch(TweetsGetter):
'''
キーワードでツイートを検索
'''
def __init__(self, keyword):
super(TweetsGetterBySearch, self).__init__()
self.keyword = keyword
def specifyUrlAndParams(self):
'''
呼出し先 URL、パラメータを返す
'''
url = 'https://api.twitter.com/1.1/search/tweets.json'
params = {'q':self.keyword, 'count':100, 'tweet_mode':"extended"}
return url, params
def pickupTweet(self, res_text):
'''
res_text からツイートを取り出し、配列にセットして返却
'''
results = []
for tweet in res_text['statuses']:
results.append(tweet)
return results
def getLimitContext(self, res_text):
'''
回数制限の情報を取得 (起動時)
'''
remaining = res_text['resources']['search']['/search/tweets']['remaining']
reset = res_text['resources']['search']['/search/tweets']['reset']
return int(remaining), int(reset)
class TweetsGetterByUser(TweetsGetter):
'''
ユーザーを指定してツイートを取得
'''
def __init__(self, screen_name):
super(TweetsGetterByUser, self).__init__()
self.screen_name = screen_name
def specifyUrlAndParams(self):
'''
呼出し先 URL、パラメータを返す
'''
url = 'https://api.twitter.com/1.1/statuses/user_timeline.json'
params = {'screen_name':self.screen_name, 'count':200, 'tweet_mode':"extended"}
return url, params
def pickupTweet(self, res_text):
'''
res_text からツイートを取り出し、配列にセットして返却
'''
results = []
for tweet in res_text:
results.append(tweet)
return results
def getLimitContext(self, res_text):
'''
回数制限の情報を取得 (起動時)
'''
remaining = res_text['resources']['statuses']['/statuses/user_timeline']['remaining']
reset = res_text['resources']['statuses']['/statuses/user_timeline']['reset']
return int(remaining), int(reset)
if __name__ == '__main__':
#ツイート取得日
today = datetime.date.today()
# 検索条件を指定して取得 (screen_nameまたはキーワード)
targets = ['recruiter_take','Syukatsu_Muso','shukatsu_mirai','es_shibamon','saiyoking','beyond_mylife','f_shukatsu25','fight_arai','sasukecareer','eruto1121','topsyuchannel','dossun_jack','gaishi_syukatu1','shukatu_man','unistyleyoppi','unistylehyt','esquestion','unistyleinc','KHsyukatu','syukatsu_mikata','Start_OfferBox','jobhun_app','badassceo','osatoexcel']
for target in targets:
getter = TweetsGetter.byUser(target) #ユーザー名(screen_name)検索の場合はこっち
# getter = TweetsGetter.bySearch(target) #キーワード検索の場合はこっち
# プロフィール蘭のURL取得フラグ(Trueで取得)
url_get_flg = False
# ファイルに保存する
fname = str(today) + "_twitter_search_target_" + target + ".csv"
with open(fname, 'w') as fs:
#ヘッダー部分
fs.write('ツイートID' + '\t'
+ 'ツイートURL' + '\t'
+ 'ツイート日時' + '\t'
+ 'ツイート本文' + '\t'
+ 'いいね数' + '\t'
+ 'RT数' + '\t'
+ 'ツイートユーザー名' + '\t'
+ 'ツイートユーザーID' + '\t'
+ 'フォロワー数' + '\t'
+ '場所' + '\t'
+ 'URL' + '\n')
cnt = 0
for tweet in getter.collect(total = 3000):
if tweet['user']['url'] is None:
prof_url = ""
elif not url_get_flg:
prof_url = "非処理"
elif get_redirect_url(tweet['user']['url']) is None:
prof_url = ""
else:
prof_url = get_redirect_url(tweet['user']['url'])
fs.write(tweet['id_str'] + '\t'
+ 'https://twitter.com/' + tweet['user']['screen_name'] + '/status/' + tweet['id_str'] + '\t'
+ YmdHMS(tweet['created_at']) + '\t'
+ tweet['full_text'].replace('\n', '[改行]') + '\t'
+ str(tweet['favorite_count']) + '\t'
+ str(tweet['retweet_count']) + '\t'
+ tweet['user']['name'] + '\t'
+ tweet['user']['screen_name'] + '\t'
+ str(tweet['user']['followers_count']) + '\t'
+ tweet['user']['location'] + '\t'
+ prof_url + '\n')
cnt += 1
print ('------ %d' % cnt)
print ('{} {} {}'.format(tweet['id'], tweet['created_at'], '@'+tweet['user']['screen_name']))
print (tweet['full_text'])
#

{kind=link}